




Hello everyone !! If you are running your workloads on the AWS EKS cluster, you may explore the rules and limitations of node group scaling to provision the deployments dynamically. This blog will explore the node lifecycle management solutions AWS Lab's Karpenter, an alternative approach to the frequently used Cluster Autoscaler solution.
Kubernetes Autoscaling
Autoscaling allows you to dynamically adjust to demand without manual intervention through metrics or events. Without autoscaling, there will be considerable efforts to provision the (scaling up or down) resources. When the running conditions change, and optimal resource utilization and managing the cloud spending is challenging. The cluster is always running at peak capacity to ensure availability or not meeting peak demand as they don't have enough resources.
When it comes to the Kubernetes Autoscaling, there are two different layers,
- Pod Level Autoscaling (Horizontal - HPA, and Vertical - HPA)
- Node Level Autoscaling
Pod Level Autoscaling
Horizontal Pod Autoscaling (Scaling out) - dynamically increase or decrease the number of running pods per your application's usage changes.
Vertical Pod Autoscaling (Scaling up) - scale the given deployments vertically within a cluster by reconciling the pods' size ( CPU or memory targets) based on their current usage and the desired target.
HPA and VPA essentially make sure that all of the services running in your cluster can dynamically handle the demand.
Node Level Autoscaling
Node Level autoscaling solves the issue - to scale the nodes in the cluster when the existing nodes are overloaded or pending to be scheduled with newly scaled pods or scale down when the nodes are underutilized.
There is already an industry-adopted, open-source, and vendor-neutral tool - Cluster Autoscaler that automatically adjusts the cluster size (by adding or removing nodes) based on the presence of pending pods and node utilization metrics. It uses the existing cloud building blocks (Autoscaling Group on AWS) for scaling. The challenges in the cluster autoscaler are the limitations on node groups, and the scaling is tightly bound to the scheduler.
Karpenter
Karpenter is a node lifecycle management solution - incubating in AWS Labs, OSS, and vendor-neutral. It observes incoming pods and launches the right instances for the situation. Instance selection decisions are intent-based and driven by the specification of incoming pods, including resource requests and scheduling constraints.
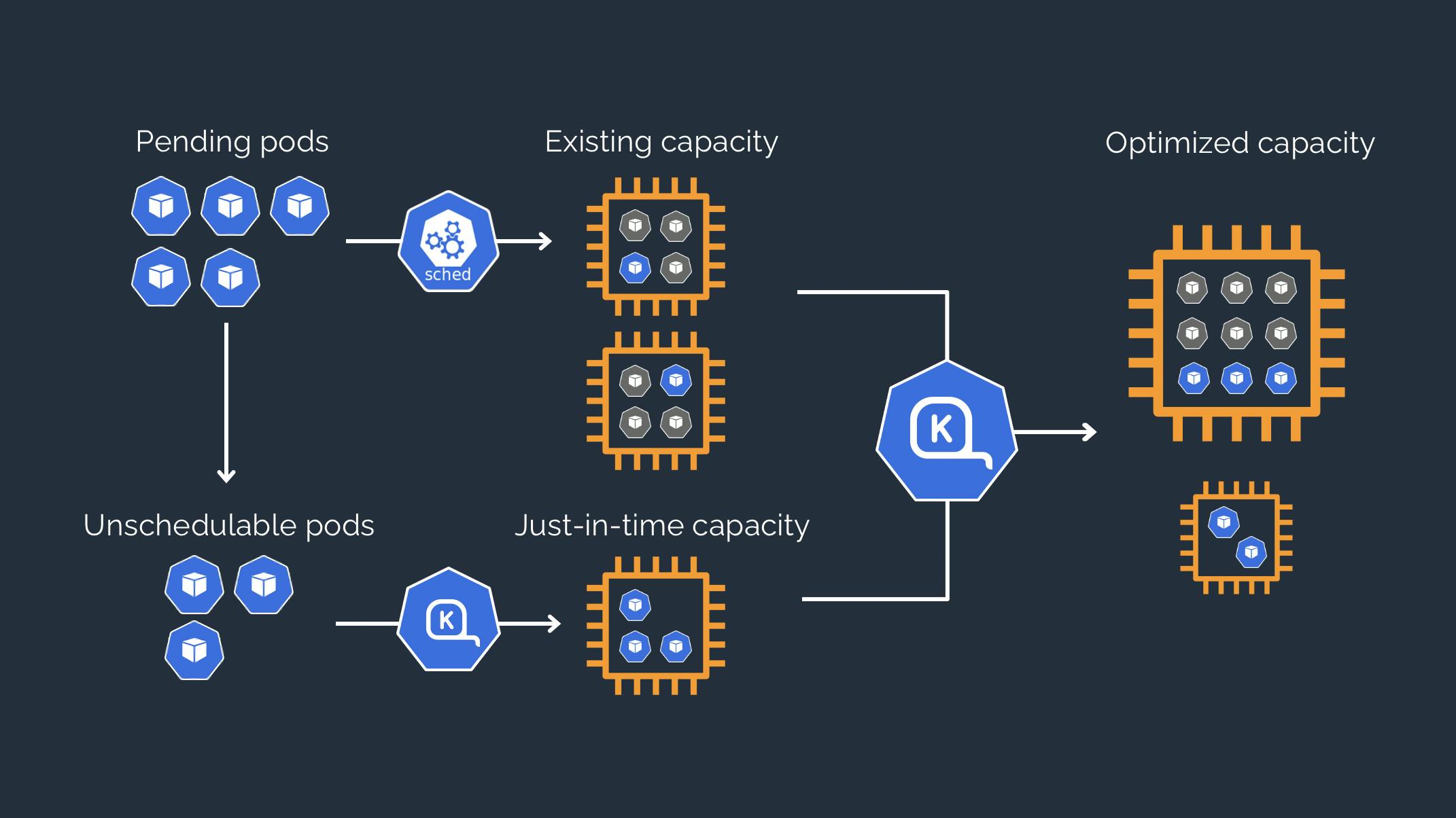
How does it work?
- Observes the pod resource requests of unscheduled pods
- Direct provision of Just-in-time capacity of the node. (Groupless Node Autoscaling)
- Terminating nodes if outdated
- Reallocating the pods in nodes for better resource utilization
Karpenter has two control loops that maximize the availability and efficiency of your cluster.
- Allocator - Fast-acting controller ensuring that pods are scheduled as quickly as possible
- Reallocator - Slow-acting controller replaces nodes as pods capacity shifts over time.
Getting started
In this section, we will quickly see the node lifecycle scenarios using Karpenter in an AWS EKS cluster. Create necessary IAM roles for Karpenter autoscaler with the cloud formation template and Create EKS cluster with the below config file using eksctl. Please refer to the documentation here.
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: eks-karpenter-demo
region: us-east-1
availabilityZones:
- us-east-1a
- us-east-1b
managedNodeGroups:
- name: eks-karpenter-demo-ng
instanceType: t3.medium
minSize: 1
maxSize: 5
You need to enable the service account and auth-config map accounts to the Karpenter. Please refer to the document here.
Install the karpenter helm chart.
helm repo add karpenter https://awslabs.github.io/karpenter/charts
helm repo update
helm upgrade --install karpenter karpenter/karpenter --namespace karpenter \
--create-namespace --set serviceAccount.create=false --version 0.3.3
Configure the Karpenter Provisioner
Configure the Karpenter provisioner as below. Please check the provider spec for more details.
apiVersion: karpenter.sh/v1alpha3
kind: Provisioner
metadata:
name: default
spec:
cluster:
name: eks-karpenter-demo
endpoint: <CLUSTER_ENDPOINT>
instanceTypes:
- t3.medium
ttlSecondsAfterEmpty: 30
Deployment
Let's do the deployment to check the launching capacity and terminating capacity features.
kubectl create deployment inflate --image=public.ecr.aws/eks-distro/kubernetes/pause:3.2
Provisioning Nodes
Scale the deployment and check out the logs in the Karpenter controller.
kubectl scale deployment inflate --replicas=10
Check the logs of the karpenter controller
➜ eks-karpenter-demo git:(main) kubectl logs -f -n karpenter $(kubectl get pods -n karpenter -l karpenter=controller -o name)
2021-09-23T04:46:11.280Z INFO controller.allocation.provisioner/default Starting provisioning loop {"commit": "bc99951"}
2021-09-23T04:46:11.280Z INFO controller.allocation.provisioner/default Waiting to batch additional pods {"commit": "bc99951"}
2021-09-23T04:46:12.452Z INFO controller.allocation.provisioner/default Found 9 provisionable pods {"commit": "bc99951"}
2021-09-23T04:46:13.689Z INFO controller.allocation.provisioner/default Computed packing for 9 pod(s) with instance type option(s) [t3.medium] {"commit": "bc99951"}
2021-09-23T04:46:16.228Z INFO controller.allocation.provisioner/default Launched instance: i-0174aa47fe6d1f7b4, type: t3.medium, zone: us-east-1b, hostname: ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:46:16.265Z INFO controller.allocation.provisioner/default Bound 9 pod(s) to node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:46:16.265Z INFO controller.allocation.provisioner/default Watching for pod events {"commit": "bc99951"}
The allocation controller listens for pods changes. It launched a new instance and bound the provision-able pods into the new nodes by working with kube-scheduler.
The provisioning time is fast compared to other node management solutions. The other node management solutions usually take 3 min to 6 min for the node to be available. After deploying the pods, the instances are immediately created and binding. The provisioner decides to launch a new instance within a second, and the node joins the cluster for under 60 seconds. Within 60 seconds, the nodes are available to cluster for running pods.
You can configure the instance types, capacity type, os, architecture, and other provisioner spec fields.
Terminating Nodes
Now, delete the deployment inflate. After 30 seconds (ttlSecondsAfterEmpty - Termination grace period), Karpenter should terminate the empty nodes - cordon & drain by listening to the rebalance and termination events.
2021-09-23T04:46:18.953Z INFO controller.allocation.provisioner/default Watching for pod events {"commit": "bc99951"}
2021-09-23T04:49:05.805Z INFO controller.Node Added TTL to empty node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:49:35.823Z INFO controller.Node Triggering termination after 30s for empty node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:49:35.849Z INFO controller.Termination Cordoned node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
2021-09-23T04:49:36.521Z INFO controller.Termination Deleted node ip-192-168-116-109.ec2.internal {"commit": "bc99951"}
Next Steps
Autoscaling nodes are always challenging. Karpenter addresses key areas of challenges by eliminating Node Group and directly provision nodes. Karpenter is easy to configure, high-performance portable solution, and vendor-agnostic. It scales seamlessly working alongside native kube-scheduler and efficiently responds to dynamic resource requests.
Check out the AWS Labs Karpenter Roadmap. It's still in beta. In the year 2021, Karpenter is going to focus on covering the majority of known use cases and plan to rigorously test it for scale and performance.
I'm Siva - working as Sr. Software Architect at Computer Enterprises Inc from Orlando. I'm an AWS Community builder, Auth0 Ambassador and I am going to write a lot about Cloud, Containers, IoT, and Devops. If you are interested in any of that, make sure to follow me if you haven’t already. Please follow me @ksivamuthu Twitter or check out my blogs at blog.sivamuthukumar.com